
Join us in the next HAWG meeting to learn more about all of this: time=18:00:00 timezone=Europe/Madrid
Hardware accelerated ROS 2 pipelines
For the last year, the ROS 2 Hardware Acceleration WG has been driving the creation of open hardware acceleration solutions for ROS 2. We proposed an open architecture and conventions for hardware acceleration extending ROS 2 core layers[1], demonstrated 5-10x speedups for individual ROS Nodes and Components [2], and recently showed how to accelerate ROS 2 perception pipelines by increasing the perception throughput with simple graphs. This entailed not only offloading individual Nodes but also optimizing the ROS message passing infrastructure. We've been discussing this last work at https://github.com/ros-acceleration/community/issues/20.
Shortly, after tracing and benchmarking a simple 2-Node perception_2nodes graph, the results obtained hint the following:
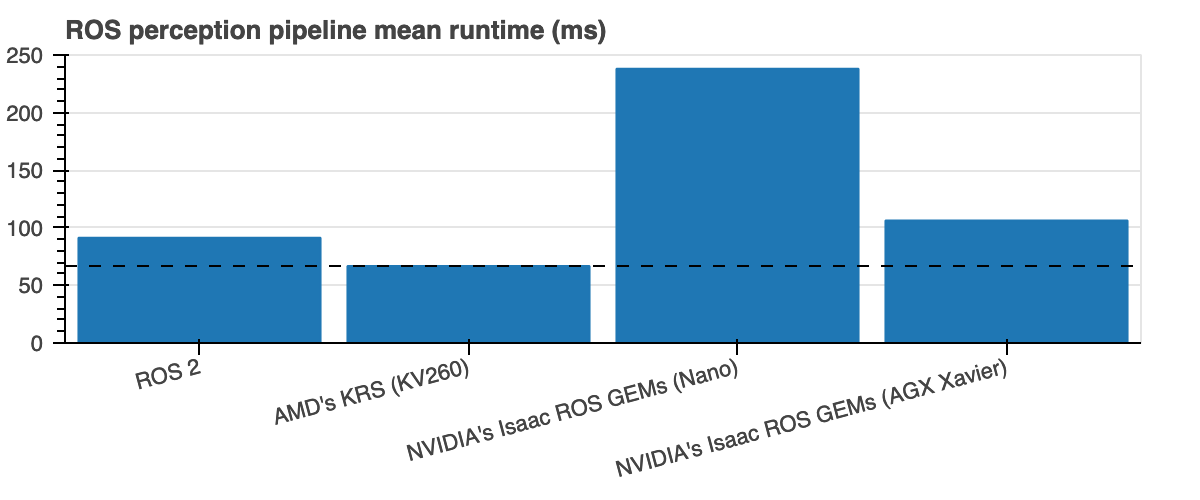
(the lower, the better)
| ROS perception pipeline runtime | Mean (speedup) |
RMS (speedup) |
|---|---|---|
| ROS 2 baseline [3] | 91.48 ms | 92.05 ms |
| AMD's KRS @ 250 MHz (Kria KV260) | 66.82 ms (1.36x) |
67.82 ms (1.35x) |
| NVIDIA's Isaac ROS GEMs (Jetson Nano 2GB) | 238.13 ms (🔻0.38x) |
243.73 ms (🔻0.37x) |
| NVIDIA's Isaac ROS GEMs (Jetson AGX Xavier) | 106.34 ms (🔻0.86x) |
107.30 ms (🔻0.85x) |
Most robots should care about energy efficency (specially mobile robots) as well. In computing, besides throughput, it's also common to present performance per watt, which is a measure of the energy efficiency of a particular computer architecture or computer hardware. Looking at those leveraging hardware acceleration above, there's almost an 8x improvement when using AMD's FPGA-enabled adaptive computing solutions:
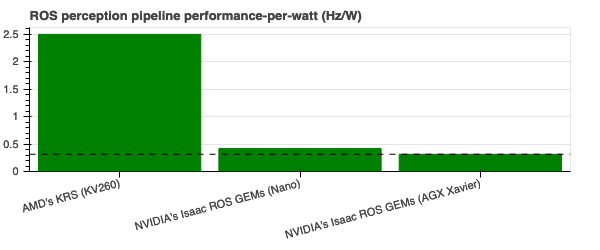
(the higher, the better)
All source code is open and available in the ros-acceleration organization. The examples used to benchmark and produce this data are at acceleration_examples. Each ROS computational graph instrumented with LTTng was traced for 60 seconds, which was then used to produce comparisons. As far as this testing goes and for the particular case of perception_2nodes, there's currently a clear benefit of using ROS 2 with AMD's solutions (through ROS 2 superset Kria Robotics Stack) as opposed to using NVIDIA's Isaac ROS GEMs, or the conventional ROS 2 in CPUs for ROS 2 perception which is used as a baseline comparison.
The downside of AMD's approach though is that it comes at the cost of having to re-architect the ROS computational graph, merging Components as most appropriate to fully exploit parallelism, while breaking the ROS modularity and granularity assumptions conveyed in the default perception stack. To accomodate this, we looked further into reducing the overhead of the ROS 2 message passing infrastructure by proposing an intra-FPGA ROS 2 communication queue.
An intra-FPGA ROS 2 communication queue: ROS 2 supertopics
To simplify usability of hardware acceleration, we prototyped ROS 2 perception components (see discussion) that leverage more complex hardware acceleration capabilities. In particular, besides offloading computations to the FPGA, each ROS Component uses an AXI4-Stream interface to create an intra-FPGA ROS 2 communication queue which is then used to pass data across Nodes through the FPGA. I call these intra-FPGA ROS 2 communication queues supertopics. These allow to avoid completely the ROS 2 message-passing system and optimizes dataflow while at same time, keeps the granularity and modularity of the ROS 2 perception stack intact, so that using these don't require you to re-architect your ROS graphs.
Results obtained with these supertopics are pretty promising. Though they perform slightly worse than if one re-architects the graph completely, the usability benefit is huge:
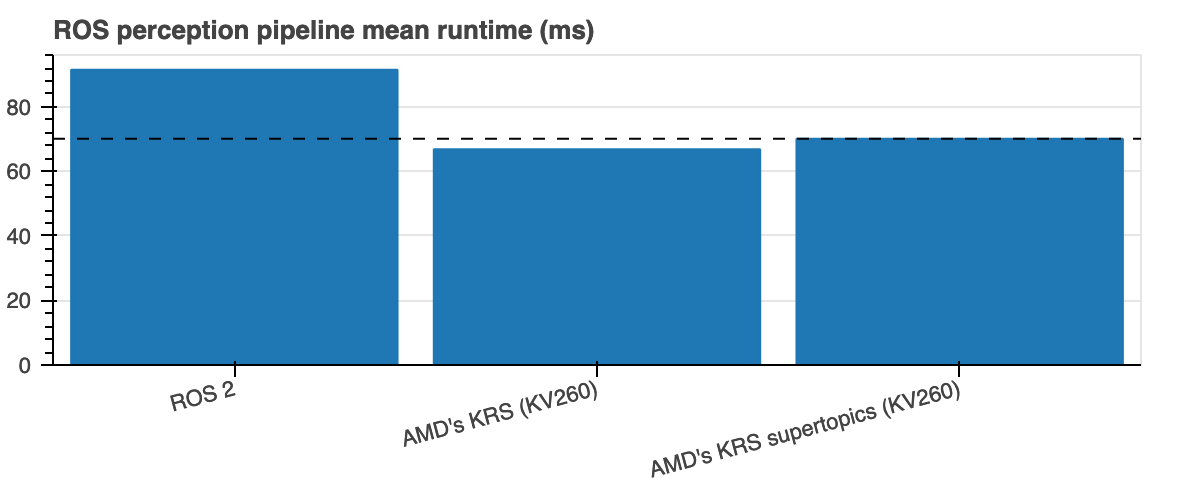
(the lower, the better)
| ROS perception pipeline runtime | Mean | RMS |
|---|---|---|
| ROS 2 baseline [3:1] | 91.48 ms | 92.05 ms |
| AMD's KRS @ 250 MHz (Kria KV260) | 66.82 ms (1.36x) |
67.82 ms (1.35x) |
| AMD's KRS supertopics @ 250 MHz (Kria KV260) | 70.13 ms (1.30x) |
71.06 ms (1.29x) |
What's exciting about these supertopics is that the speedup can be exploited for every chained Node in the perception graph. More complex graphs involving more than 2 Nodes will get a significant additional boost. On the critical side, the current prototype is quite basic and each supertopic only supports static (build-time defined) single-producer -> single consumer interactions. This can be improved in the future by annotating data and duplicating data streams (e.g. streamDup and friends) to make these queues more flexible and dynamic.
Contributing NVIDIA adapters for the ROS 2 Hardware Acceleration architecture
Dealing with NVIDIA Isaac ROS GEMs has been pretty fun but there's definitely room for improvement since getting it to work took quite some hacks. In an attempt to align this work better with common ROS 2 development flows, I've contributed a firmware layer that matches with the ROS 2 open architecture for hardware acceleration and which was used to produce comparisons. For now, the contributions rely on NVIDIA's VPI (which is shipped in the pre-cook rootfs) but the structure considers future CUDA enablement in ROS 2 cross-compilation flows [4]. Ultimately, these packages should allow building accelerators for NVIDIA GPU platforms in the same way you can build today AMD FPGA kernels.
- https://github.com/ros-acceleration/isaac_ros_image_pipeline (fork contributing ROS_CUDA enablement and LTTng instrumentation)
- https://github.com/ros-acceleration/acceleration_firmware_jetson_nano
- https://github.com/ros-acceleration/ament_cuda
All resources to reproduce results should be available. Firmware is very preliminary, so ping me if you give it a try and have feedback.
New Subproject: Robotic Processing Unit (RPU)
As discussed, it seems pretty obvious by now that ROS 2 stacks are slowly starting to be ported to hardware acceleration leading solutions. This is exciting times for the community and for the WG. However based on the experience this past year, there's no best solution that will fit all use cases. To obtain additional performance, compute platforms in robotics must map ROS computational graphs efficiently to CPUs, but also to specialized hardware including FPGAs and GPUs as appropriate. In other words, robotic chips and robot cores should map ROS computational graphs not just to CPUs, but also to FPGAs, GPUs and other compute technologies available to obtain best performance.
In an attempt to consolidate the group's progress into an incremental series of open demonstrators that complement acceleration_examples and evolves with the WG and the community, I'm happy to present a new subproject for the ROS 2 Hardware Acceleration Working Group that sets a long term ambitious goal: the design of a Robotic Processing Unit (RPU)[5], robot-specific processors that map ROS computational graphs efficiently to CPUs, FPGAs and GPUs to obtain best peformance.
Briefly, the vision is that RPUs will empower robots with the ability to react faster, consume less power, and deliver additional real-time capabilities with their custom compute architectures that fit best the usual robotics pipelines. This includes tasks across sensing, perception, mapping, localization, motion control, low-level control and actuation. To be clear, the objective of this subproject is not to design a new physical device and instead, existing development platforms will be used to prototype a robot-specific processing unit that performs best when it comes to ROS 2 computational graphs.
Currently, I have well defined use cases that allow evaluating sensing, perception and actuation. At this stage, I'm looking to collect community feedback and input on additional use cases that cover mapping, localization, motion control and low-level control. If you have input and/or are willing to help with the Robotic Processing Unit, please fill in the Robotic Processing Unit (RPU) input request form.
If you wish to learn more about the Robotic Processing Unit and/or participate in the subproject contributing to its development and architecture, join the ROS 2 Hardware Acceleration WG meetings (next one).
See https://github.com/ros-acceleration/community#architecture and https://github.com/ros-infrastructure/rep/pull/324 ↩︎
See https://github.com/ros-acceleration/acceleration_examples/tree/main/nodes ↩︎
I just didn't work on it because the ROS Nodes above don't use CUDA directly. ↩︎
Sorry for the collision with the Real-Time Processing Unit, if you have a better name suggestion, ping me. ↩︎