Robots moving faster require faster perception computations happening at the edge. This article discusses how hardware acceleration empowers faster robots and how it's important to select the right accelerator. Benchmarking results hint speedup differences of more than 500x between accelerarion solutions for ROS Nodes.
Moving faster (or with more dexterity) requires faster perception computations happening at the edge. Atlas below uses perception to identify, navigate and jump around obstacles. Edge perception is key to navigate under environments that change, which are most in the human world. Atlas leverages a time-of-flight depth camera to generate point clouds of the environment at 15 Hz. The point cloud is a large and dense collection of range measurements which needs to be processed at the edge (directly in the robot) for smooth behaviors, reducing any latency from the sensors and all the way into the actuators. By leveraging hardware acceleration, Atlas’ perception extracts surfaces from this point cloud which are then used to plan actions in the order of tenths of milliseconds. All of this happens thanks to hardware acceleration.
Data obtained in a robot from its sensors like cameras and LIDAR is typically fed into the perception layer turning into something useful for decision making and planning physical actions. Perception helps sense the static and dynamic objects, and build a reliable and detailed representation of the robot's environment using computer vision and machine learning techniques. The perception layer in a robot is thereby responsible for object detection, segmentation and tracking. Traditionally, a perception pipeline starts with image pre-processing, followed by a region of interest detector and then a classifier that outputs detected objects. ROS 2 provides various pre-built Nodes (Components more specifically) that can be used to build perception pipelines easily.
A previous article introduced how hardware acceleration helped accelerate ROS 2 computational graphs (including perception ones). But taking a step back from Graphs and looking at Nodes helps address the following question:
which accelerator (GPU, FPGA, etc) is the best one for each one of our ROS 2 Nodes?
This requires additional understanding and benchmarking.
Understanding the different accelerators for robots
A robot is a system of systems, one that comprises sensors to perceive its environment, actuators to act on it, and computation to process it all, while responding coherently and in time to its application. Most robots exchange information across their internal networks while meeting timing deadlines. Both determinism and latency are critical in robotics since in a way, a robot is a network of time sensitive networks.
Robots have limited onboard resources and those designed only with CPUs struggle while scaling due to fixed memory and compute capabilities. To meet these timing deadlines, robots can leverage hardware acceleration and create custom compute architectures. The core idea behind hardware acceleration is to combine the traditional control-driven approach used in robotics (via CPUs), with the data-driven one optimizing the amount of hardware resources and, as a consequence, improving the performance.
The most popular accelerators used in robotics are FPGAs and GPUs:
- FPGAs: FPGAs are both software and hardware programmable, and deliver complete flexibility and capabilities to build mixed control and data-driven compute models mixing different hard and soft processors. ROS 2 Nodes can instruct FPGAs to "build hardware" for the particular task being executed, exploiting parallelism and building custom memory structures to favour the dataflow. The downside of FPGAs though is complexity. Architects creating hardware with FPGAs need to pre-allocate the different tasks into different compute units to fully exploit performance. In a nutshell, pre-built FPGA-friendly ROS 2 Nodes are still rare, and hard to build.
- GPUs: like CPUs, GPUs have also a fixed hardware architecture (they aren't hardware reprogrammable) but have many (many) more cores. A single instruction can process a thousand pieces of data or more, though, typically, the same operation must be performed on every data point being simultaneously processed. The atomic processing elements operate on a data vector (as opposed to a data point in the case of CPUs), but still perform one fixed instruction per ALU. Data, thereby, must also still be brought to these processing units from memory via a fixed datapaths. This impacts ROS Nodes heavily and remains an open issue to be addressed.
You can read more about the different compute substrates used in robotics in [1].
Benchmarking hardware acceleration in ROS 2 Nodes for perception
To compare ROS 2 Nodes for Perception tasks across FPGA and GPU accelerators we pick AMD's Kria KV260 FPGA-enabled board and NVIDIA's Jetson Nano with an onboard GPU. Both present a somewhat similar CPU (KV260 features a quad-core A53 whereas Jetson Nano a quad-core A57) and have a similar ROS behavior from a CPU-centric perspective. For benchmarking, we follow the benchmarking approach described in REP-2008 PR. In particular, for creating the acceleration kernels, we leverage both AMD's Vitis Vision Library and NVIDIA's Vision Programming Interface. For example, to compare a ROS 2 Perception Node using the Harris Corner Detector algorithm, we leverage [2] and [3] respectively for FPGA and GPU comparison. In addition, we leverage AMD's HLS and NVIDIA's CUDA also respectively, where appropriate.
To discriminate between any possible differences between the A53 cores in KV260 and the A57 cores in Jetson Nano, measurements capture the acceleration kernels runtime in milliseconds (ms) and discard both the ROS 2 message-passing infrastructure overhead, and the host-device (GPU or FPGA) to CPU data transfer overhead.
The results obtained across perception ROS 2 Nodes hint that FPGAs outperform GPUs in robotics perception by a 500x speedup difference in popular algorithms such as the Histogram of Oriented Gradients (HOG):
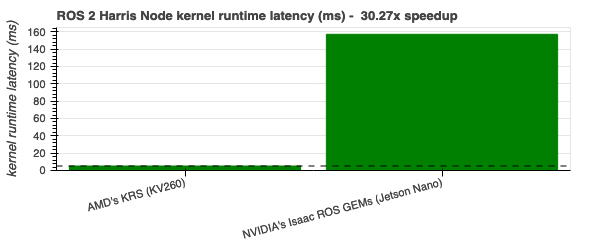
ROS 2 Harris Node - 30.27x |
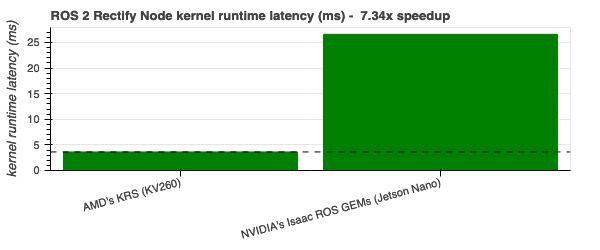
ROS 2 Rectify Node - 7.34x |
|---|---|
 |
 |
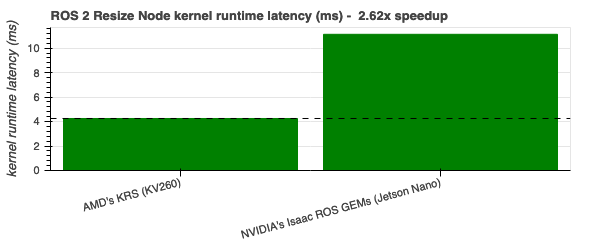
ROS 2 Resize Node - 2.62x |
Histogram of Oriented Gradients - 509.52x |
 |
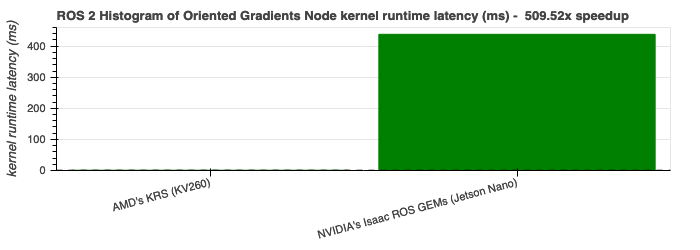 |
Canny Edge Tracing - 3.26x |
Fast Corner Detection - 8.43x |
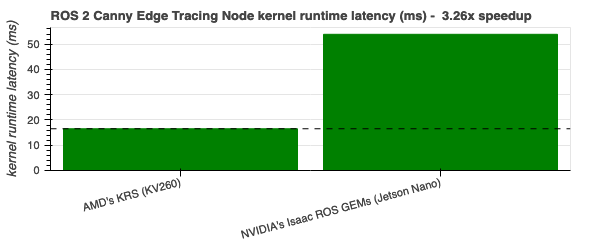 |
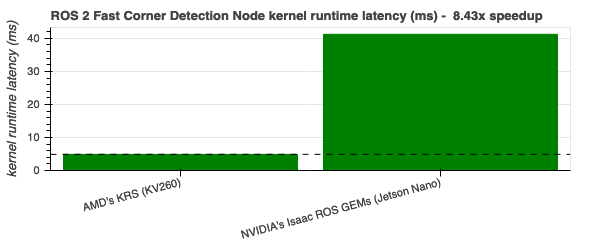 |
Gaussian Difference - 11.94x |
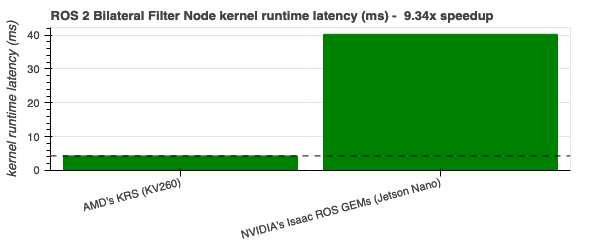
Bilateral Filter - 9.33x |
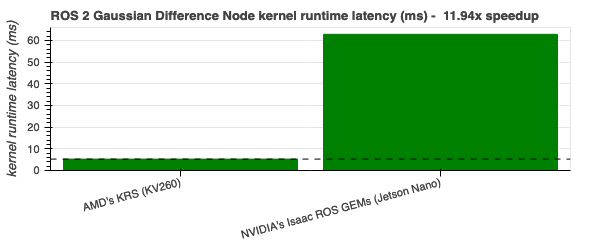 |
 |
While measuring power consumption, we also observe that the FPGA designs are much more power efficient and present a performance-per-watt figure that's on average 5x better than their GPU counterparts. Performance-per-watt is an interesting figure to take into account when looking at robots, particularly mobile robots.
Further improving hardware acceleration in ROS 2
For perception Nodes, FPGAs seem to outperform significantly their acceleration counterparts, however, as usual with reprogrammable hardware, this comes at the cost of complexity while hardware-software codesigning. Simplifying the development flow for roboticists requires creating common architectures and conventions and that's why we've contributing to REP-2008 - ROS 2 Hardware Acceleration Architecture and Conventions.
Further improving ROS 2 requires one to combine the computation technologies together, in the right manner and for each task: CPUs, GPUs, and FPGAs. Keep an eye in the ROS 2 Hardware Acceleration Working Group if finding the right combination is something you're interested.
Mayoral-Vilches, V., & Corradi, G. (2021). Adaptive computing in robotics, leveraging ros 2 to enable software-defined hardware for fpgas. arXiv preprint arXiv:2109.03276. https://docs.xilinx.com/v/u/en-US/wp537-adaptive-computing-robotics ↩︎
AMD Vitis Vision Library. Harris Corner Detector. https://xilinx.github.io/Vitis_Libraries/vision/2021.2/api-reference.html?highlightharris-corner-detection#harris-corner-detection ↩︎
NVIDIA VPI. Harris Corner. https://docs.nvidia.com/vpi/group__VPI__HarrisCorners.html ↩︎